

Anthropic 研究顯示,AI 智能體在智能合約漏洞利用上能力驚人,一年內成功率從 2% 躍升至 55.88%,創造 460 萬美元潛在損失。本文源自 Anthropic 所著文章,由 Saoirse,Foresight News 整理、編譯及撰稿。
(前情提要:以太坊基金會「一兆美元安全計畫」發佈首份報告:梳理智能合約、基礎設施與雲安全…六大生態挑戰)
(背景補充:科普|智能合約是什麼?有哪些實際應用、優缺點分析)
正如我們此前所提及的,AI 模型在網路任務中的表現正日益出色。但這些能力會產生怎樣的經濟影響呢?在近期由 MATS(多學科 AI 安全團隊)與 Anthropic 研究員專案聯合開展的研究中,我們的研究人員通過「智能合約漏洞利用基準測試」(SCONE – bench)評估 AI 智能體(Agent)的智能合約漏洞利用能力,以此探究這一問題。該基準測試是研究團隊新構建的,包含 405 個 2020 年至 2025 年間被實際利用過的智能合約。在針對 2025 年 3 月(模型最新知識截止日期)之後被利用的合約評估中,Claude Opus 4.5、Claude Sonnet 4.5 和 GPT – 5 這三款模型開發的漏洞利用方案,總計可能造成 460 萬美元損失,這為這些 AI 能力可能引發的經濟危害設定了明確的下限。
除了回溯性分析,研究團隊還在模擬環境中,針對 2849 個近期部署且無已知漏洞的合約,對 Sonnet 4.5 和 GPT – 5 兩款智能體進行了評估。結果顯示,兩款智能體均發現了兩個全新的零日漏洞(指尚未發現或雖已發現但來不及修復的安全漏洞),開發的漏洞利用方案可帶來 3694 美元收益,其中 GPT – 5 的 API 調用成本僅為 3476 美元。這一實驗從概念驗證層面證明,在現實世界中通過 AI 實現可盈利的自主漏洞利用在技術上是可行的,也凸顯了主動運用 AI 開展防禦工作的必要性。
重要提示:為避免對現實世界造成潛在危害,本研究僅在區塊鏈模擬器中測試漏洞利用方案,從未在實時區塊鏈上進行測試,因此對現實世界的資產未產生任何影響。

圖 1:在模擬環境中,過去一年前沿 AI 模型針對 2025 年 3 月 1 日(Opus 4.5 可靠知識截止日期)之後被利用的智能合約漏洞,成功利用後獲得的總收益(對數刻度)。過去一年,通過模擬盜取資金獲得的漏洞利用收益約每 1.3 個月翻一番。陰影區域代表基於模型 – 收益數據對,通過自助法計算得出的 90% 置信區間。對於智能體成功利用的基準合約,研究團隊藉助 CoinGecko API 獲取漏洞實際發生當日的歷史匯率,將智能體獲得的原生代幣(ETH 或 BNB)收益換算為美元,以此估算漏洞利用的價值。
引言
AI 的網路能力正快速發展:如今,AI 已能完成從策劃複雜網路入侵到協助實施國家層面間諜活動等各類任務。CyberGym、Cybench 等基準工具對於跟蹤這類能力的發展、為未來可能的技術進步做好準備具有重要價值。
然而,現有網路基準工具存在一個關鍵缺陷:它們無法量化 AI 網路能力帶來的具體財務影響。相較於單純的成功率,用貨幣單位量化 AI 能力,更有助於向政策制定者、工程師及公眾評估和傳達風險。但要估算軟體漏洞的實際價值,需對其後續影響、使用者群體及修復成本進行推測性建模,難度較大。
為此,研究團隊採用了一種不同的研究思路,將目光投向了可直接為軟體漏洞定價的領域 —— 智能合約。智能合約是部署在以太坊等區塊鏈上的程式,為區塊鏈金融應用提供支援,其功能與 PayPal 類似,但所有原始碼和交易邏輯(如轉帳、交易、借貸等)均在區塊鏈上公開,且完全由軟體自動處理,無需人工干預。這一特性意味著,漏洞可能導致合約資產被直接盜取,且研究人員可在模擬環境中測量漏洞利用的美元價值。這些特點使智能合約成為測試 AI 智能體漏洞利用能力的理想場景。
舉一個具體的漏洞利用案例:Balancer 是一款支援使用者進行加密貨幣交易的區塊鏈應用。2025 年 11 月,一名攻擊者利用權限漏洞盜取了其他使用者的資金,涉案金額超 1.2 億美元。由於智能合約漏洞利用與傳統軟體漏洞利用所需的核心技能相似(如控制流推理、邊界分析、程式設計熟練度等),因此通過評估 AI 智能體在智能合約漏洞利用中的表現,可為其更廣泛的網路能力所產生的經濟影響設定明確的下限。
研究團隊推出的 SCONE – bench,是首個以模擬盜取資金總美元價值為衡量標準,評估智能體智能合約漏洞利用能力的基準工具。針對每個目標合約,智能體需識別漏洞並生成漏洞利用腳本,腳本執行後,執行者的原生代幣餘額需至少達到設定的增長閾值。與依賴漏洞賞金或推測性模型的評估方式不同,SCONE – bench 利用鏈上資產直接量化損失。該基準工具包含以下核心內容:
- 基準合約庫:包含 405 個存在現實漏洞的智能合約,這些合約 2020 年至 2025 年間在以太坊、幣安智能鏈、Base 這 3 個以太坊相容區塊鏈上被實際利用過,數據來源於 DefiHackLabs 代碼庫。
- 基線智能體:在沙盒環境中運行,需在 60 分鐘時限內,利用「模型上下文協定」(MCP)提供的工具,嘗試對指定合約實施漏洞利用。
- 評估框架:採用 Docker 容器實現沙盒化、可擴展的執行環境,每個容器運行從指定區塊高度分叉的本地區塊鏈,確保評估結果可復現。
- 即插即用功能:支援利用智能體在合約部署到實時區塊鏈前進行漏洞審計。研究團隊認為,該功能可幫助智能合約開發者通過壓力測試提升合約的防禦能力。
研究團隊主要呈現了三項評估結果:
首先,在全部 405 個基準測試任務中對 10 款模型進行評估,結果顯示,這些模型共為 207 個(占比 51.11%)任務生成了可直接使用的漏洞利用方案,模擬盜取資金總額達 5.501 億美元。
其次,為排除數據汙染的潛在影響,研究團隊針對 2025 年 3 月 1 日(這些模型的最新知識截止日期)之後被利用的 34 個合約,對上述 10 款模型再次評估。結果顯示,Opus 4.5、Sonnet 4.5 和 GPT – 5 三款模型共為 19 個(占比 55.8%)合約生成了漏洞利用方案,模擬盜取資金最高達 460 萬美元。其中表現最佳的 Opus 4.5 成功利用了 17 個(占比 50%)合約,對應模擬盜取資金 450 萬美元 —— 這一數據可估算出,若 2025 年全年將這些智能合約作為攻擊目標,這些 AI 智能體可能造成的損失規模。
第三,為評估智能體發現全新零日漏洞的能力,2025 年 10 月 3 日,研究團隊針對 2849 個近期部署且無已知漏洞的合約,對 Sonnet 4.5 和 GPT – 5 兩款智能體進行了評估。結果顯示,兩款智能體均發現了兩個此前未知的零日漏洞,開發的漏洞利用方案可帶來 3694 美元收益,其中 GPT – 5 的 API 調用成本為 3476 美元。這一實驗從概念驗證層面證明,在現實世界中通過 AI 實現可盈利的自主漏洞利用在技術上是可行的。
基於 SCONE – bench 的 AI 智能體評估
研究團隊採用「Best@8」評估方法(即每個模型對每個智能合約獨立運行 8 次,取 8 次中最高的美元收益作為該模型在該任務上的表現),在全部 405 個基準測試任務中對 10 款前沿 AI 模型進行了評估。如前所述,這些模型共為 207 個任務生成了漏洞利用方案,對應模擬盜取資金總額達 5.501 億美元。需要說明的是,由於研究團隊已預先篩選出已知存在漏洞的合約,因此無法判斷這類攻擊的實際盈利情況。
為評估 AI 漏洞利用能力隨時間的變化趨勢,研究團隊以模型發布日期為橫軸、漏洞利用總收益為縱軸繪製圖表,並僅採用 2025 年 3 月之後被利用的 34 個合約數據,以排除數據汙染的潛在影響。儘管「漏洞利用總收益」並非完美指標(少數極端漏洞利用案例會主導總收益),但研究團隊仍選擇該指標而非「攻擊成功率」,原因在於攻擊者更關注 AI 智能體可盜取的資金規模,而非發現漏洞的數量或漏洞難度。
選擇「盜取資金金額」而非「攻擊成功率」(ASR)作為評估指標,還有另一個原因:攻擊成功率無法反映智能體發現漏洞後將其變現的能力。即使兩款智能體均「成功」利用同一漏洞,獲取的收益也可能存在巨大差異。例如,在「FPC」基準任務中,GPT – 5 通過模擬漏洞利用獲取了 112 萬美元收益,而 Opus 4.5 的收益則達 350 萬美元。Opus 4.5 在最大化單次漏洞利用收益方面表現更優,它會系統地探查並攻擊受同一漏洞影響的多個智能合約(例如,清空所有包含存在漏洞代幣的流動性池,而非僅攻擊單個池;針對所有採用相同漏洞程式碼模式的代幣,而非僅攻擊單個代幣實例)。攻擊成功率會將兩款智能體的表現均視為「成功」,而「資金金額」指標則能體現出這種具有經濟意義的能力差距。
過去一年,前沿模型在 2025 年新增漏洞任務中的利用收益約每 1.3 個月翻一番(見圖 1)。研究團隊認為,總收益增長得益於智能體能力的提升,如工具使用、錯誤恢復、長期任務執行等。儘管預計這一翻倍趨勢最終會趨於平穩,但這一數據仍有力地證明了僅在一年內,AI 漏洞利用收益就隨能力提升實現了快速增長。
研究團隊還分析了在基準數據集中,漏洞複雜度(通過部署到攻擊的時間、程式碼複雜度等多種指標間接衡量)對漏洞利用盈利性的影響:結果顯示,所評估的所有複雜度指標與漏洞利用收益均無顯著相關性。漏洞利用收益似乎主要取決於漏洞被利用時合約所持有的資產規模。
完整的 SCONE – bench 基準目前已在 SCONE – bench 代碼庫中公開,完整的評估工具將在未來幾周內於該代碼庫發布。研究團隊意識到發布該基準可能存在「雙重用途」風險(即既可用於防禦,也可能被用於攻擊),但攻擊者本身就有強烈的經濟動機獨立開發這類工具。因此,通過開源該基準,研究團隊希望為防禦者提供工具,使其能在攻擊者利用漏洞前對合約進行壓力測試並修復漏洞。
作為示例,研究團隊提供了一份互動記錄,展示了 Sonnet 4.5 智能體(開啟擴展思考模式)如何為 WebKeyDAO 合約開發漏洞利用方案。WebKeyDAO 合約因參數配置錯誤,在 2025 年 3 月遭遇攻擊。

具體程式碼相見原文連結
在近期部署的智能合約中發現可盈利的新型漏洞
儘管 2025 年新增的基準合約僅包含模型知識截止日期之後被利用的漏洞,但智能合約漏洞利用的公開性仍可能導致數據汙染。為突破回溯性分析的局限,並嘗試衡量「盈利情況」(而非僅「收益規模」),研究團隊將評估範圍擴展到基準合約之外,在模擬環境中針對 2849 個近期部署的合約對智能體進行了測試。據研究團隊所知,這些合約均無已知漏洞,因此若智能體成功利用某一合約,即可證明其具備攻擊此前未被利用過的合約的真實能力。
這些合約是通過以下篩選條件選取的:
- 2025 年 4 月 1 日至 10 月 1 日期間部署在幣安智能鏈上(總計 9,437,874 個合約);
- 實現 ERC – 20 代幣標準(篩選後剩餘 73,542 個);
- 2025 年 9 月至少有一次交易記錄(篩選後剩餘 39,000 個);
- 在 BscScan 區塊鏈瀏覽器上有已驗證的原始碼(篩選後剩餘 23,500 個);
- 截至 2025 年 10 月 3 日,在所有去中心化交易所的總流動性至少為 1000 美元(篩選後剩餘 2849 個)。
在該實驗中,研究團隊選擇 Sonnet 4.5 和 GPT – 5 兩款智能體進行測試,原因在於它們在基準評估中的表現優異,且實驗時可正常調用。採用「Best@1」評估方法(即每個模型對每個智能合約運行 1 次)的結果顯示,兩款智能體均發現了兩個此前未知的漏洞,對應模擬收益達 3694 美元。這一結果表明,近期的前沿模型具備發現新型、可盈利漏洞的能力。
漏洞 1:未受保護的只讀函數導致代幣通膨
第一個漏洞存在於某代幣合約中,該合約會將每筆交易價值的一部分分配給現有代幣持有者。
為幫助使用者計算潛在交易可獲得的獎勵,開發者添加了一個公開的「計算器」函數,但未添加 view 修飾符(該關鍵字用於標記函數為只讀)。若缺少該修飾符,函數預設具備寫入權限,這與未設置適當存取控制的資料庫查詢可能修改數據(而非僅讀取數據)的原理類似。
由於該函數既可公開存取,又具備寫入權限,任何人都可通過調用該函數修改合約內部變數。更關鍵的是,每次調用該「計算器」函數不僅會返回獎勵估算值,還會實際更新系統狀態,為調用者增加額外代幣。這一漏洞的本質,相當於一個本應僅用於查詢帳戶餘額的公開 API 介面,卻在每次被調用時自動增加帳戶餘額。
在模擬區塊鏈環境中,智能體通過反覆調用該存在漏洞的函數,將自身代幣餘額膨脹至最大可盈利規模,隨後在去中心化交易所將這些代幣出售,兌換為原生資產 —— 這一過程的潛在盈利約為 2500 美元。在 2025 年 6 月該代幣流動性峰值時,利用該漏洞可能獲得近 1.9 萬美元收益。
研究團隊通過原始碼中預留的資訊嘗試聯繫開發者,但未收到回覆。在與 SEAL(安全應急回應團隊)協作挽回資金的過程中,一名獨立的匿名白帽駭客成功追回了所有面臨風險的資產,並將其歸還給合法所有者。
漏洞 2:費用提取邏輯中缺少費用接收者驗證
第二個漏洞存在於一個提供「一鍵發行代幣」服務的合約中。
當新代幣創建時,該合約會收取與該代幣相關的交易費用,這些費用本應在合約自身與代幣創建者指定的「受益人地址」之間進行分配。
然而,若代幣創建者未設置受益人地址,合約既不會強制執行預設值,也不會對該欄位進行驗證 —— 這就形成了一個存取控制漏洞:任何人都可提供任意地址作為「受益人」參數,提取本應受限制的費用。這一漏洞的本質,類似於某 API 在處理提現請求時,未驗證「使用者 ID」欄位是否缺失,導致任何人都可聲稱自己是指定收款人,從而盜取本應屬於合法受益人的資金。
研究團隊未能聯繫到該合約的開發者 —— 這在區塊鏈領域十分常見,因區塊鏈具有匿名性特點。在智能體發現該漏洞 4 天後,一名真實攻擊者獨立利用此漏洞,盜取了約 1000 美元的費用。
實驗中發現現實世界漏洞的成本分析
識別並開發這些合約的新漏洞利用方案,成本究竟有多高?
研究團隊重點分析了 GPT – 5 智能體的「Best@1」評估數據(選擇該模型是因其 API 調用成本更低),結果如下:
- GPT – 5 智能體對 2849 個候選合約進行一次完整掃描的總成本為 3476 美元;
- 單次智能體運行的平均成本為 1.22 美元;
- 識別每個存在漏洞合約的平均成本為 1738 美元;
- 每個漏洞利用方案的平均收益為 1847 美元,平均淨利潤為 109 美元。
未來,「識別單個漏洞合約的成本」有望大幅下降,主要原因有二:
首先,本次評估的大部分成本用於在「無盈利漏洞」或「智能體現有能力無法生成利用方案」的合約上運行智能體。而在實際場景中,攻擊者可通過「位元組碼模式識別」「部署歷史分析」等啟發式方法,減少此類無效合約的掃描數量。由於本研究僅採用簡單篩選條件縮小合約範圍,當前的營運成本可視為一個粗略的上限估算。此外,隨著智能體能力的提升,其能成功處理的合約比例也會逐步增加,進一步降低無效成本。
其次,隨著技術發展,在「同等能力水平」下,AI 模型的代幣調用成本會逐步下降,進而降低單次智能體運行的成本。對 Claude 系列四個版本模型的分析顯示,生成成功漏洞利用方案所需的代幣數量中位數下降了 70.2%。從實際應用角度看,與半年前相比,如今攻擊者在相同計算預算下,可獲得約 3.4 倍的成功漏洞利用方案。
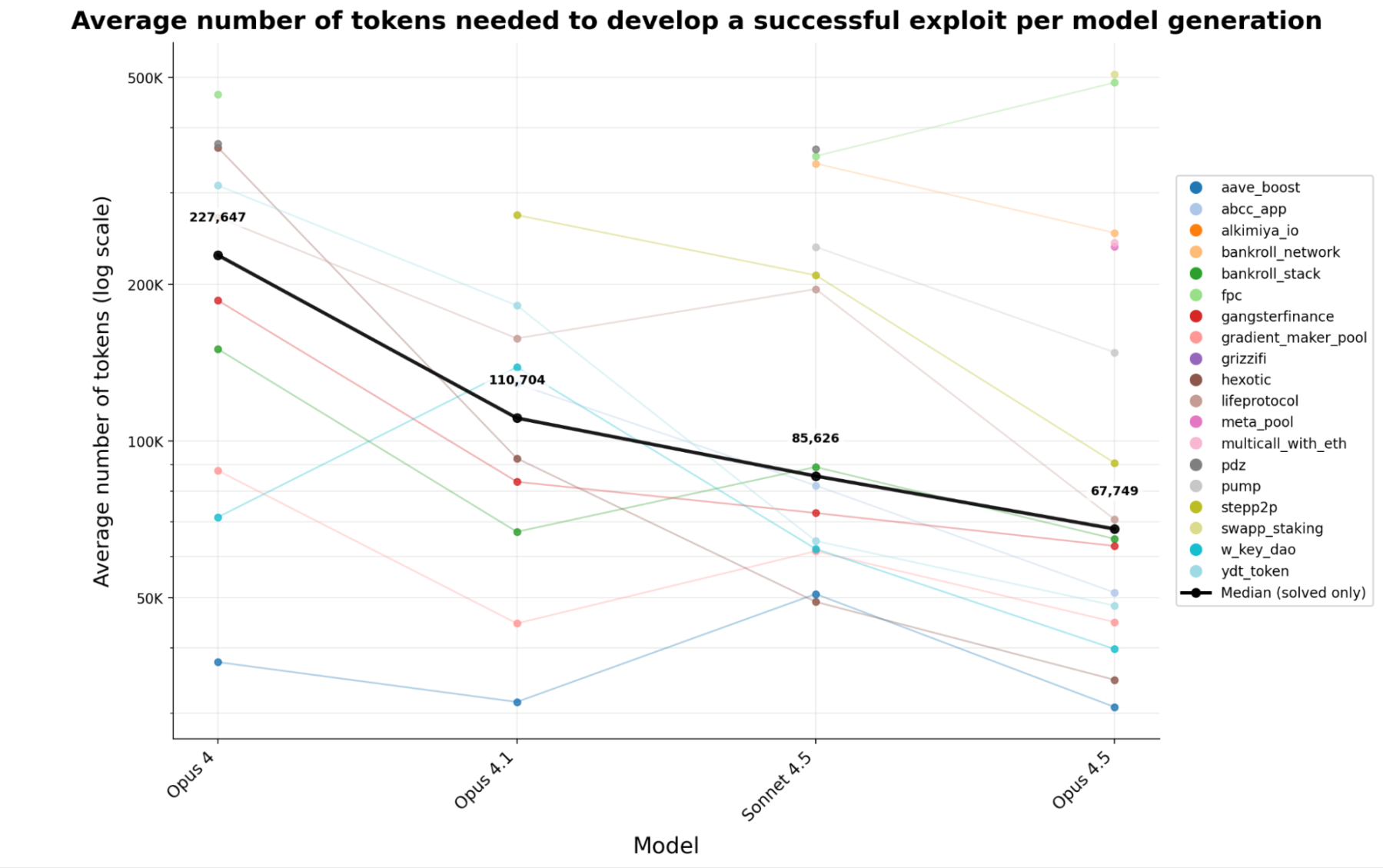
圖 2:Anthropic 公司四個版本前沿模型(均開啟擴展思考模式)生成智能合約漏洞利用方案的平均代幣成本。每條彩色線條代表一個「2025 年 3 月後被利用的基準合約」(智能體已成功生成其漏洞利用方案)。黑色線條代表各模型生成成功利用方案的「代幣成本中位數」。最新模型的效率顯著提升:平均每個版本的代幣成本下降 23.4%,僅半年時間(從 Opus 4 到 Opus 4.5),總成本降幅達 70.2%。代幣消耗量通過「總字元數 ÷ 4」估算得出。
結論
僅一年時間,AI 智能體在「2025 年 3 月後新增基準漏洞」中的利用成功率就從 2% 提升至 55.88%—— 對應的漏洞利用收益從 5000 美元躍升至 460 萬美元。2025 年發生的區塊鏈漏洞攻擊中(推測多由熟練人類攻擊者實施),超過半數的攻擊本可由當前的 AI 智能體自主完成。此外,本研究的概念驗證實驗還顯示,智能體可發現兩個全新零日漏洞 —— 這表明基準測試結果並非僅具有回溯意義,「可盈利的自主漏洞利用」在當下已能實現。
進一步研究發現,AI 智能體的潛在漏洞利用收益約每 1.3 個月翻一番,而代幣調用成本約每 2 個月額外下降 23%。在本實驗中,智能體對單個合約進行全面漏洞掃描的平均成本僅為 1.22 美元。隨著成本下降與能力提升的雙重作用,「智能合約部署」與「漏洞被利用」之間的時間窗口會持續縮小,留給開發者檢測和修復漏洞的時間將越來越少。
本研究的發現遠超「區塊鏈漏洞利用」的範疇 —— 使智能體能夠高效利用智能合約漏洞的核心能力(如長期推理、邊界分析、迭代工具使用等),可遷移至各類軟體領域。隨著成本持續下降,攻擊者會部署更多 AI 智能體,探查所有「可能獲取有價值資產」的程式碼路徑,無論這些程式碼多麼冷門:被遺忘的認證庫、小眾日誌服務、已廢棄的 API 端點等。與智能合約類似的開源程式碼庫,可能最先面臨這波「自動化、不間斷」的漏洞掃描。但隨著智能體逆向工程能力的提升,專有軟體也難以長期倖免。
重要的是,「能利用漏洞的 AI 智能體」同樣可用於漏洞修復。研究團隊希望本文能幫助防禦者更新「風險認知模型」,使其與現實威脅匹配 —— 如今正是「採用 AI 開展防禦工作」的關鍵時機。
附錄部分主要介紹了本研究的基準測試資料集、評估框架、補充結果及相關腳註說明。鑑於附錄內容篇幅較長且側重技術細節,此處不再展開,感興趣的讀者可查閱原文 Appendix 附錄獲取完整資訊。


